
http://apologeticspress.org/APContent.aspx?category=9&article=203
Cracking the Code—The Human Genome Project in Perspective [Part I]
| by | Bert Thompson, Ph.D. |
[EDITOR’S NOTE: Immediately after the July issue of Reason and Revelation had gone to the printer, the non-profit Human Genome Project in the United States and its international analogue, the non-profit Human Genome Organization, along with Celera Genomics, a for-profit corporation, announced that working together they had deciphered, for all practical purposes, the genetic code contained in the human genome. We were not able to “stop the presses” on the July issue in order to discuss this momentous feat, but hope that R&R readers will enjoy our two-part series on this amazing scientific accomplishment and its implications for humankind. The reader may find it useful to have on hand the “Genetic Glossary,” since some terms in that glossary are employed here for the first time.]
On Monday, June 26, 2000, the President of the United States and the Prime Minister of Great Britain jointly called a press conference that not only received instantaneous, worldwide news coverage, but also captured the attention of people around the globe (see Office of Technology Policy, 2000). As the ambassadors of Japan, Germany, and France watched (along with some of the planet’s most distinguished scientists, who had joined them either in person or via satellite), the two world leaders announced what one science writer called “the greatest intellectual moment in history, bar none!”—the deciphering of the genetic code contained in the entire human genome.
The news media—both popular and scientific—had a field day. The (July 3, 2000) bright red cover of Time magazine screamed in huge, yellow letters—“Cracking the Code!” Upon opening the magazine to read the text of the cover story, the reader was met with an audacious headline in giant type that announced: “The Race Is Over!” The July 3 issue of U.S. News & World Reportcovered the story under the heading, “We’ve Only Just Begun” (Fischer, 2000, 129[1]:47). One week later, in its July 10 issue, U.S. News & World Report assigned its highly touted editor-at-large, David Gergen, to write an editorial that was titled “Collaboration? Very Cool” about the success of the joint effort (2000, 129[2]:64). The July 3 issue of Newsweek contained a feature article, “A Genome Milestone,” discussing the project (Hayden, 2000, 129[1]:51). The June 30 issue of Science, the official organ of the American Association for the Advancement of Science (Marshall, 2000, 288:2294-2295), and the June 29 issue of Nature, the official organ of its counterpart in Great Britain, the British Association for the Advancement of Science (Macilwain, 2000, 405:983-984), each devoted in-depth stories to the “cracking of the code.” The July 2000 issue of Scientific American also weighed in (Brown, 2000, 283[1]:50-55), as did numerous other professional journals in countries on almost every continent.
Emotional exhilaration ran high, and descriptive adjectives flowed freely. Professional writers, as well as some of the scientists directly involved in the events that led to the decoding of the human genome, variously described the results as the “holy grail” of biology and “the most important scientific effort that mankind has ever mounted”—and did not hesitate to compare the saga to the Manhattan Project that developed the atomic bomb in the mid-1940s or the Apollo Project that landed men on the moon on July 20, 1969. Time’s cover story authors remarked authoritatively: “It’s impossible to overstate the significance of this achievement” (Golden and Lemonick, 2000, 156[1]:19).
Amidst all the hoopla, important questions are bound to arise. For example, what, exactly, is the human genome? What do scientists mean when they say they have “decoded” it? What do these events mean for mankind—either now or in the future? What are the potential benefits and/or drawbacks associated with such research? When can humanity expect to experience them? Are there any scientific, biblical, ethical, or moral implications to be considered? If so, what are they and how should we handle them? These kinds of questions often accompany the invention and development of major new scientific technologies, and deserve a well-reasoned, informed response.
THE SCIENCE OF GENETICS
One of the newest (and certainly one of the most exciting) sciences is that of genetics. After all, every living thing—plant, animal, or human—is a storehouse of genetic information and therefore is a potential “laboratory” full of scientific knowledge. Genetics had its origin in 1865 as the result of studies performed by an Augustinian monk, Gregor Mendel, whose accomplishments certainly are worthy of recognition. Philosopher Richard von Mises stated, in fact, that Mendel’s work “plays in genetics a role comparable to that of Newton’s laws in mechanics” (1968, p. 243).
Gregor Mendel died in 1884, never realizing that eventually he would be known as the “father of modern genetics” (see Considine, 1976, p. 1155). Many scientists since have added to the knowledge he provided in regard to this important new science. For example, in 1902, German embryologist Theodor Boveri, and in 1904, American cytologist W.S. Sutton, building on the work of another German embryologist, Wilhelm Roux, documented that what Mendel had referred to as Anlagen (genes?) were distributed throughout the body in the nucleus of every cell in sausage-shaped bodies that Roux called “chromosomes” (from the Greek meaning “color body,” because early geneticists had to stain them with brightly colored dyes in order to view them under a microscope).
The effort to locate a gene, determine what it does, and discover how it functions was launched in 1906 when American scientist Thomas H. Morgan began his famous studies on the chromosomes of fruit flies. That same year, at a meeting of the Royal Horticultural Society, English biologist William Bateson suggested the term “genetics” as the name for this new science (see Asimov, 1972, p. 516). In 1908, Morgan identified “invisible heredity units” (that later would come to be known as genes) as being associated with portions of chromosomes. Then, in 1909, Danish botanist Wilhelm Johannsen coined the term “gene” (from the Greek for “giving birth to”) as the name for these “heredity units”—a term still in use today (see Bishop and Waldholz, 1999, p. 23). [Johannsen also coined the two terms “genotype” and “phenotype” to describe an individual’s inner genetic make-up, and the outward expression of that make-up, respectively.]
The physical location of the gene, therefore, has been known only since the beginning of this century. Shortly thereafter, it became clear that almost every biochemical characteristic in all living creatures was determined by genes. In 1911, scientists produced the first chromosome maps. In the 1940s, O.T. Avery showed that traits could be passed from one bacterium to another by a chemical known as DNA (see Avery, et al., 1944, 79:137-158). The eminent taxonomist of Harvard, Ernst Mayr, wrote concerning this event: “A new era in developmental genetics was opened when Avery demonstrated that DNA was the carrier of the genetic information” (1997, p. 166). By 1941, two Americans, George W. Beadle and Edward L. Tatum, had discovered that the genes’ function was to produce proteins—which serve both as structural components of all living matter and as enzymes that assist in the infinite variety of chemical reactions that make life possible. Yet, as Bishop and Waldholz noted:
Despite these remarkable discoveries, the exact nature of the genes remained a mystery. No one knew what a gene looked like, how it worked, or how the cell managed to replicate its genes in order to pass a complement on to its offspring. By the 1940s, however, a series of discoveries began suggesting that the genes were composed of an acid found in the nuclei of cells. This nucleic acid was rich in a sugar called deoxyribose and hence was known as deoxyribonucleic acid, or DNA (1999, p. 23).
The still-new science of genetics was advanced greatly by the discovery, in 1953, of the chemical code within cells that provides the genetic instructions. It was in that year that James D. Watson of the United States, and Francis H.C. Crick of Great Britain, published their landmark paper about the composition and helical structure of DNA (1953, 171:737-738). Nine years later, in 1962, they were awarded the Nobel Prize in Medicine or Physiology for their stellar achievement in elucidating the structure of DNA (a subject about which I will have more to say later in this article, as well as in part two of this series). British geneticist, E.B. Ford, in his book, Understanding Genetics, provided an insightful summary when he wrote:
What then keeps...living things in general “on the right lines”? Why are there not pairs of sparrows, for instance, that beget robins, or some other species of bird: why indeed birds at all? Something must be handed on from parent to offspring which ensures conformity, not complete but in a high degree, and prevents such extreme departures. What is it, how does it work, what rules does it obey and why does it apparently allow only limited variation? Genetics is the science that endeavours to answer these questions, and much else besides. It is the study of organic inheritance and variation, if we must use more formal language (1979, p. 13).
A LOOK AT THE WORKINGS OF THE CELL
As scientists have studied what Dr. Ford called “organic inheritance and variation,” we have come to realize that the basic unit of life is the cell. Genes, chromosomes, nucleic acids, and the chemicals that compose them are found within the cells of every living organism on Earth. It is quite appropriate, therefore, that an investigation into matters such as those being discussed here should begin with an examination of the structure and nature of the cell.
Anatomist Ernst Haeckel, Charles Darwin’s chief supporter in Germany in the mid-nineteenth century, once summarized his personal feelings about the “simple” nature of the cell when he wrote that it contained merely “homogeneous globules of plasm” that were
composed chiefly of carbon with an admixture of hydrogen, nitrogen, and sulfur. These component parts properly united produce the soul and body of the animated world, and suitably nursed became man. With this single argument the mystery of the universe is explained, the Deity annulled, and a new era of infinite knowledge ushered in (1905, p. 111).
Voilà! As easy as that, simple “homogeneous globules of plasm” nursed man into existence, animated his body, dispelled the necessity of a Creator, and ushered in a new era of “infinite knowledge.” In the end, however, Haeckel’s simplistic, naturalistic concept turned out to be little more than wishful thinking. As Lester and Hefley put it:
We once thought that the cell, the basic unit of life, was a simple bag of protoplasm. Then we learned that each cell in any life form is a teeming micro-universe of compartments, structures, and chemical agents—and each human being has billions of cells... (1998, pp. 30-31).
Billions of cells indeed! In the section he authored on the topic of “life” for the Encyclopaedia Britannica, the late astronomer Carl Sagan observed that a single human being is composed of what he referred to as an “ambulatory collection of 1014 cells” (1997, 22:965). He then noted: “The information content of a simple cell has been established as around 1012 bits, comparable to about a hundred million pages of the Encyclopaedia Britannica” (22:966). Evolutionist Richard Dawkins acknowledged that the cell’s nucleus “contains a digitally coded database larger, in information content, than all 30 volumes of the Encyclopaedia Britannica put together. And this figure is for each cell, not all the cells of a body put together” (1986, pp. 17-18, emp. in orig.). Dr. Sagan estimated that if a person were to count every letter in every word in every book of the world’s largest library (approximately 10 million volumes), the total number of letters would be 1012, which suggests that the “simple cell” contains the information equivalent of the world’s largest library (1974, 10:894)! Stephen C. Meyer suggested:
Since the late 1950s advances in molecular biology and biochemistry have revolutionized our understanding of the miniature world within the cell. Modern molecular biology has revealed that living cells—the fundamental units of life—possess the ability to store, edit and transmit information and to use information to regulate their most fundamental metabolic processes. Far from characterizing cells as simple “homogeneous globules of plasm,” as did Ernst Haeckel and other nineteenth-century biologists, modern biologists now describe cells as, among other things, “distributive real-time computers” and complex information processing systems (1998, pp. 113-114).
So much for the “simple” cell being a little lump of albuminous combination of carbon, as Haeckel once put it.
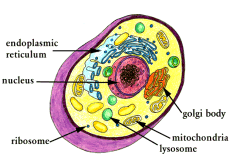 |
| Figure 1 — Simplified representation of a typical eukaryotic cell as rendered by Gabriela Weaver of Colorado University at Denver. Used by permission of Dr. Weaver and The Food Zone. |
Cells are filled with a variety of organelles such as ribosomes (which aid in protein production), Golgi bodies (which package proteins), the endoplasmic reticulum (the transport system of the cell), mitochondria (which manufacture energy), vacuoles (which aid in intracellular cleaning processes), etc. Furthermore, cells are absolute marvels of design when it comes to reproducing themselves. Cellular reproduction consists of at least two important functions—duplication of the cell’s complement of genetic material and cleavage of the cell’s cytoplasmic matrix into two distinct yet separate parts. However, not all cells reproduce in the same manner.
Speaking in general terms, there are two basic types of cells found in organisms that procreate sexually. First, there are somatic (body) cells that contain a full complement (the diploid number) of genes. Second, there are germ (egg and sperm) cells that contain half the complement (the haploid number) of genes. Likely, the reason that germ cells (gametes) contain only half the normal genetic content is fairly obvious. Since the genetic material in the two gametes is combined during procreation in order to form a zygote (which will develop first into an embryo, then into a fetus, and eventually into the neonate), in order to ensure that the zygote has the normal, standard chromosome number the gametes always must contain exactly half that necessary number. As Weisz and Keogh explained in their widely used textbook, Elements of Biology:
One consequence of every sexual process is that a zygote formed from two gametes possesses twice the number of chromosomes present in a single gamete. An adult organism developing from such a zygote would consist of cells having a doubled chromosome number. If the next generation is again produced sexually, the chromosome number would quadruple, and this process of progressive doubling would continue indefinitely through successive generations. Such events do not happen, and chromosome numbers do stay constant from one life cycle to the next (1977, p. 331).
Why is it, though, that chromosome numbers “do stay constant from one life cycle to the next?” The answer, of course, has to do with the two different types of cellular division. All somatic cells reproduce by the process known as mitosis. Most cells in sexually reproducing organisms possess a nucleus that contains a preset number of chromosomes. In mitosis, cell division is “a mathematically precise doubling of the chromosomes and their genes. The two chromosome sets so produced then become separated and become part of two newly formed nuclei” so that “the net result of cell division is the formation of two cells that match each other and the parent cell precisely in their gene contents and that contain approximately equal amounts and types of all other components” (Weisz and Keogh, 1977, pp. 322,325). Thus, mitosis carefully maintains a constant diploid chromosome number during cellular division. For example, in human somatic cells, there are 46 chromosomes. During mitosis, from the original “parent” cell two new “daughter” cells are produced, each of which then contains 46 chromosomes.
Germ cells, on the other hand, reproduce by a process known as meiosis. During this type of cellular division, the diploid chromosome number is halved (“meiosis” derives from the Greek meaning to split or divide). So, to use the example of the human, the diploid chromosome complement of 46 is reduced to 23 in each one of the newly formed cells. As Weisz and Keogh observed: “Meiosis occurs in every life cycle that includes a sexual process—in other words, more or less universally.... It is the function of meiosis to counteract the chromosome-doubling effect of fertilization by reducing a doubled chromosome number to half. The unreduced doubled chromosome number, before meiosis, is called the diploid number; the reduced number, after meiosis, is the haploid number” (p. 331, emp. in orig.). In his book, The Panda’s Thumb, evolutionist Stephen Jay Gould discussed the marvel of meiosis.
Meiosis, the splitting of chromosome pairs in the formation of sex cells, represents one of the great triumphs of good engineering in biology. Sexual reproduction cannot work unless eggs and sperm each contain precisely half the genetic information of normal body cells. The union of two halves by fertilization restores the full amount of genetic information.... This halving, or “reduction division,” occurs during meiosis when the chromosomes line up in pairs and pull apart, one member of each pair moving to each of the sex cells. Our admiration for the precision of meiosis can only increase when we learn that cells of some ferns contain more than 600 pairs of chromosomes and that, in most cases, meiosis splits each pair without error (1980, p. 160).
And it is not just meiosis that works in most instances without error. Evolutionist John Gribbin admitted, for example, that “...once a fertilized, single human cell begins to develop, the original plans are faithfully copied each time the cell divides (a process called mitosis) so that every one of the thousand million million cells in my body, and in yours, contains a perfect replica of the original plans for the whole body” (1981, p. 193, emp. added, parenthetical comment in orig.).
Regarding the “perfect replica” produced in cellular division, the late United Nations scientist A.E. Wilder-Smith observed:
The Nobel laureate, F.H. Crick has said that if one were to translate the coded information on one human cell into book form, one would require one thousand volumes each of five hundred pages to do so. And yet the mechanism of a cell can copy faithfully at cell division all this information of one thousand volumes each of five hundred pages in just twenty minutes (1976, p. 258).
Information scientist Werner Gitt remarked:
The DNA is structured in such a way that it can be replicated every time a cell divides in two. Each of the two daughter cells has to have identically the same genetic information after the division and copying process. This replication is so precise that it can be compared to 280 clerks copying the entire Bible sequentially each one from the previous one, with at most a single letter being transposed erroneously in the entire copying process.... One cell division lasts from 20 to 80 minutes, and during this time the entire molecular library, equivalent to one thousand books, is copied correctly (1997, p. 90).
But as great an engineering triumph as cellular division and reproduction are, they represent only a small part of the story regarding the marvelous design built into each living cell. As Wilder-Smith also noted, the continued construction and metabolism of a cell are “dependent upon its internal ‘handwriting’ in the genetic code. Everything, even life itself, is regulated from a biological viewpoint by the information contained in this genetic code. All syntheses are directed by this information” (1976, p. 254).
Since all living things are storehouses of genetic information (i.e., within the genetic code), and since it is this cellular code that regulates life and directs its synthesis, the importance of the study of this code hardly can be overstated.
THE GENETIC CODE—ITS FUNCTION AND DESIGN
Faithful, accurate cellular division is critically important, of course, because without it life could not continue. But neither could life sustain itself without the existence and continuation of the extremely intricate genetic code contained within each cell. Scientific studies have shown that the hereditary information contained in the code found within the nucleus of the living cell is universal in nature. Regardless of their respective views on origins, all scientists acknowledge this. Evolutionist Richard Dawkins observed: “The genetic code is universal.... The complete word-for-word universality of the genetic dictionary is, for the taxonomist, too much of a good thing” (1986, p. 270). Creationist Darrel Kautz agreed: “It is recognized by molecular biologists that the genetic code is universal, irrespective of how different living things are in their external appearances” (1988, p. 44). Or, as Matt Ridley put it in his 1999 book, Genome:
Wherever you go in the world, whatever animal, plant, bug or blob you look at, if it is alive, it will use the same dictionary and know the same code. All life is one. The genetic code, bar a few tiny local aberrations, mostly for unexplained reasons in the ciliate protozoa, is the same in every creature. We all use exactly the same language.
This means—and religious people might find this a useful argument—that there was only one creation, one single event when life was born.... The unity of life is an empirical fact (pp. 21-22, emp. added).
It is the genetic code which ensures that living things reproduce faithfully “after their kind,” exactly as the principles of genetics state that they should. Such faithful reproduction, of course, is due both to the immense complexity and the intricate design of that code. It is doubtful that anyone cognizant of the facts would speak of the “simple” genetic code. A.G. Cairns-Smith has explained why:
Every organism has in it a store of what is called genetic information.... I will refer to an organism’s genetic information store as its Library.... Where is the Library in such a multicellular organism? The answer is everywhere. With a few exceptions every cell in a multicellular organism has a complete set of all the books in the Library. As such an organism grows, its cells multiply and in the process the complete central Library gets copied again and again.... The human Library has 46 of these cord-like books in it. They are called chromosomes. They are not all of the same size, but an average one has the equivalent of about 20,000 pages.... Man’s Library, for example, consists of a set of construction and service manuals that run to the equivalent of about a million book-pages together (1985, pp. 9,10, emp. in orig.).
Wilder-Smith concurred with such an assessment when he wrote:
Now, when we are confronted with the genetic code, we are astounded at once at its simplicity, complexity and the mass of information contained in it. One cannot avoid being awed at the sheer density of information contained in such a miniaturized space. When one considers that the entire chemical information required to construct a man, elephant, frog, or an orchid was compressed into two minuscule reproductive cells, one can only be astounded. Only a sub-human could not be astounded. The almost inconceivably complex information needed to synthesize a man, plant, or a crocodile from air, sunlight, organic substances, carbon dioxide and minerals is contained in these two tiny cells. If one were to request an engineer to accomplish this feat of information miniaturization, one would be considered fit for the psychiatric line (1976, pp. 257-259, emp. in orig.).
It is no less amazing to learn that even what some would call “simple” cells (e.g., bacteria) have extremely large and complex “libraries” of genetic information stored within them. For example, the bacterium Escherichia coli, which is by no means the “simplest” cell known, is a tiny rod only a thousandth of a millimeter across and about twice as long, yet “it is an indication of the sheer complexity of E. coli that its Library runs to a thousand page-equivalent” (Cairns-Smith, p. 11). Biochemist Michael Behe has suggested that the amount of DNA in a cell “varies roughly with the complexity of the organism” (1998, p. 185). There are notable exceptions, however. Humans, for example, have about 100 times more of the genetic-code-bearing molecule (DNA) than bacteria, yet salamanders, which are amphibians, have 20 times more DNA than humans (see Hitching, 1982, p. 75). Humans have roughly 30 times more DNA than some insects, yet less than half that of certain other insects (see Spetner, 1997, p. 28).
It does not take much convincing, beyond facts such as these, to see that the genetic code is characterized by orderliness, complexity, and adeptness in function. The order and complexity themselves are nothing short of phenomenal. But the function of this code is perhaps its most impressive feature, as Wilder-Smith explained when he suggested that the coded information
...may be compared to a book or to a video or audiotape, with an extra factor coded into it enabling the genetic information, under certain environmental conditions, to read itself and then to execute the information it reads. It resembles, that is, a hypothetical architect’s plan of a house, which plan not only contains the information on how to build the house, but which can, when thrown into the garden, build entirely of its own initiative the house all on its own without the need for contractors or any other outside building agents.... Thus, it is fair to say that the technology exhibited by the genetic code is orders of magnitude higher than any technology man has, until now, developed. What is its secret? The secret lies in its ability to store and to execute incredible magnitudes of conceptual information in the ultimate molecular miniaturization of the information storage and retrieval system of the nucleotides and their sequences (1987, p. 73, emp. in orig.).
This “ability to store and to execute incredible magnitudes of conceptual information” is where DNA comes into play. In their book, The Mystery of Life’s Origin, Thaxton, Bradley, and Olsen discussed the DNA-based genetic code elucidated by Crick and Watson.
According to their now-famous model, hereditary information is transmitted from one generation to the next by means of a simple code resident in the specific sequence of certain constituents of the DNA molecule.... The breakthrough by Crick and Watson was their discovery of the specific key to life’s diversity. It was the extraordinarily complex yet orderly architecture of the DNA molecule. They had discovered that there is in fact a code inscribed in this “coil of life,” bringing a major advance in our understanding of life’s remarkable structure (1984, p. 1).
How important is the “coil of life” represented in the DNA molecule? Wilder-Smith concluded: “The information stored on the DNA-molecule is that which controls totally, as far as we at present know, by its interaction with its environment, the development of all biological organisms” (1987, p. 73). Professor E.H. Andrews summarized how this can be true:
The way the DNA code works is this. The DNA molecule is like a template or pattern for the making of other molecules called “proteins.” ...These proteins then control the growth and activity of the cell which, in turn, controls the growth and activity of the whole organism (1978, p. 28).
Thus, the DNA contains the information that allows proteins to be manufactured, and the proteins control cell growth and function, which ultimately are responsible for each organism. The genetic code, as found within the DNA molecule, is vital to life as we know it. In his book, Let Us Make Man, Bruce Anderson referred to it as “the chief executive of the cell in which it resides, giving chemical commands to control everything that keeps the cell alive and functioning” (1980, p. 50). Kautz followed this same line of thinking when he stated:
The information in DNA is sufficient for directing and controlling all the processes which transpire within a cell including diagnosing, repairing, and replicating the cell. Think of an architectural blueprint having the capacity of actually building the structure depicted on the blueprint, of maintaining that structure in good repair, and even replicating it (1988, p. 44).
Likely, many people have not considered the exact terminology with which the genetic code is described in the scientific literature. Lester and Bohlin observed:
The DNA in living cells contains coded information. It is not surprising that so many of the terms used in describing DNA and its functions are language terms. We speak of the genetic code. DNA is transcribed into RNA. RNA is translated into protein.... Such designations are not simply convenient or just anthropomorphisms. They accurately describe the situation (1984, pp. 85-86, emp. in orig.).
Kautz thus concluded:
The information in the DNA molecule had to have been imposed upon it by some outside source just as music is imposed on a cassette tape. The information in DNA is presented in coded form as explained previously, and codes are not known to arise spontaneously.... Further, consider that human beings have learned to store information on clay tablets, stone, papyrus, paper, film, magnetic media such as audio and video cassettes, microchips, etc. Yet human technology has not yet advanced to the point of storing information chemically as it is in the DNA molecule (1988, pp. 44,45, emp. in orig.).
How, then, did this complex chemical code arise? What “outside source” imposed the information on the DNA molecule? And where does the Human Genome Project fit into all of this?
REFERENCES
Anderson, Bruce L. (1980), Let Us Make Man (Plainfield, NJ: Logos International).
Andrews, E.H. (1978), From Nothing to Nature (Welwyn, Hertfordshire, England: Evangelical Press).
Asimov, Isaac (1972), Isaac Asimov’s Biographical Encyclopedia of Science and Technology (New York: Avon).
Avery, O.T., C.M. MacLeod, and M. McCarty (1944), “Studies on the Chemical Nature of the Substance Inducing Transformation of Pneumococcal Types,” Journal of Experimental Medicine, 79:137-158.
Behe, Michael J. (1998), “Intelligent Design Theory as a Tool for Analyzing Biochemical Systems,” Mere Creation, ed. William A. Dembski (Downers Grove, IL: InterVarsity Press).
Bishop, Jerry E. and Michael Waldholz (1999), Genome: The Story of the Most Astonishing Scientific Adventure of Our Time—The Attempt to Map All the Genes in the Human Body (Lincoln, NE: toExcel Publishers).
Brown, Kathryn (2000), “The Human Genome Business Today,” Scientific American, 283[1]:50-55, July.
Cairns-Smith, A.G. (1985), Seven Clues to the Origin of Life (Cambridge, England: Cambridge University Press).
Considine, Douglas M. (1976), Van Nostrand’s Scientific Encyclopedia (New York: Van Nostrand Reinhold), fifth edition.
Dawkins, Richard (1986), The Blind Watchmaker (New York: W.W. Norton).
Fischer, Joannie Schrof (2000), “We’ve Only Just Begun,” U.S. News & World Report, 129[1]:47, July 3.
Ford, E.B. (1979), Understanding Genetics (New York: Pica Press).
Gergen, David (2000), “Collaboration? Very Cool,” U.S. News & World Report, 129[2]:64, July 10.
Gitt, Werner (1997), In the Beginning Was Information (Bielefeld, Germany: Christliche Literatur-Verbreitung).
Golden, Frederic and Michael D. Lemonick (2000), “The Race Is Over,” Time, 156[1]:19-23, July 3.
Gould, Stephen J. (1980), “Dr. Down’s Syndrome,” The Panda’s Thumb (New York: W.W. Norton), pp. 160-176.
Gribbin, John (1981), Genesis: The Origins of Man and the Universe (New York: Delacorte).
Haeckel, Ernst (1905), The Wonders of Life, trans. J. McCabe (London: Watts).
Hayden, Thomas (2000), “A Genome Milestone,” Newsweek, 136[1]:51, July 3.
Hitching, Francis (1982), The Neck of the Giraffe (New York: Ticknor and Fields).
Kautz, Darrel (1988), The Origin of Living Things (Milwaukee, WI: Privately published by the author).
Lester, Lane and Raymond Bohlin (1984), The Natural Limits of Biological Change (Grand Rapids, MI: Zondervan).
Macilwain, Colin (2000), “World Leaders Heap Praise on Human Genome Landmark,” Nature, 405:983-984, June 29.
Marshall, Eliot (2000), “Rival Genome Sequencers Celebrate a Milestone Together,” Science, 288:2294-2295, June 30.
Mayr, Ernst (1997), This is Biology (Cambridge, MA: Belknap Press of Harvard University).
Mendel, Gregor (1865), Experiments in Plant Hybridization, reprinted in J.A. Peters, ed. (1959), Classic Papers in Genetics (Englewood Cliffs, NJ: Prentice-Hall).
Meyer, Stephen C. (1998), “The Explanatory Power of Design: DNA and the Origin of Information,” Mere Creation, ed. William A. Dembski (Downers Grove, IL: InterVarsity Press).
Office of Technology Policy—The White House (2000) Remarks by the President—The Entire Human Genome Project, [On-line], http://www.whitehouse.gov/WH/EOP/OSTP/html/00628_2.html.
Ridley, Matt (1999), Genome: Autobiography of a Species in 23 Chapters (New York: HarperCollins).
Sagan, Carl (1974), “Life on Earth,” Encyclopaedia Britannica (New York: Encyclopaedia Britannica, Inc.), 10:894ff.
Sagan, Carl (1997), “Life,” Encyclopaedia Britannica (New York: Encyclopaedia Britannica, Inc.), 22:964-981.
Spetner, Lee M. (1997), Not By Chance (Brooklyn, NY: Judaica Press).
von Mises, Richard (1968), Positivism (New York: Dover).
Watson, James D. and Francis H.C. Crick (1953), “Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid,” Nature, 17:737-738.
Weisz, Paul B. and Richard N. Keogh (1977), Elements of Biology (New York: McGraw-Hill).
Wilder-Smith, A.E. (1976), A Basis for a New Biology (Einigen: Telos International).
Wilder-Smith, A.E. (1987), The Scientific Alternative to Neo-Darwinian Evolutionary Theory (Costa Mesa, CA: TWFT Publishers).
No comments:
Post a Comment